
 Julius Simonelli & Ilsoo Seong
Julius Simonelli & Ilsoo Seong
How Property Intelligence Leverages Generative AI & Large Language Models
For two decades, technology has flooded insurers with data, the sheer volume of which has become more overwhelming than it is actionable....

Machine learning can be divided up into two basic types: supervised and unsupervised. In supervised learning, machines are trained on datasets individually labeled by humans. In unsupervised learning, machines analyze unlabeled datasets, organizing and clustering them based on similarities and differences they detect themselves. While both types have their benefits and drawbacks, we believe that unsupervised learning represents great potential for the future of machine learning, both for Betterview and for the property intelligence industry at large.
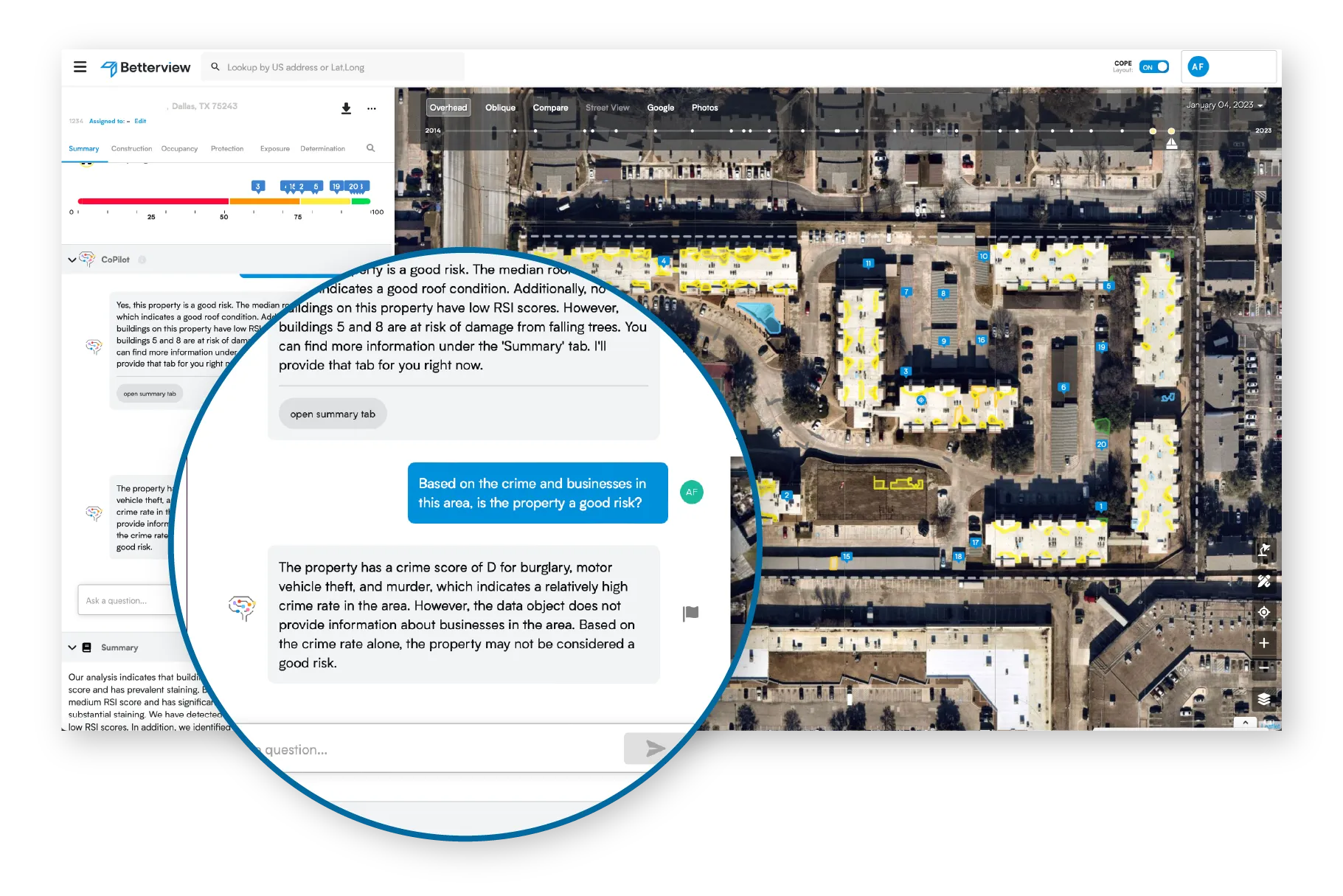
To understand the importance of machine learning to the insurtech industry, you first need to understand the term property intelligence. Property intelligence refers to a diverse array of insights, datasets, and tools that can be used to analyze, score, manage, and monitor real property risk. One of the most powerful forms of property intelligence is high-quality geospatial imagery that has been analyzed with computer vision algorithms. Computer vision can detect specific risk drivers on a property, such as missing shingles on a roof, insufficient defensible space, and dozens of other attributes.
As with all machine learning algorithms, this process can be either supervised or unsupervised. In the case of the former, every image must be labeled beforehand to identify the presence of roof staining, ponding, and whatever else the algorithm is looking for. This is a painstaking and time-consuming process, especially for larger insurers who are writing books of hundreds of thousands of properties. In addition, human error can lead to inaccurate detections, defeating the purpose of property intelligence. While it is true that nearly all computer vision products today rely on supervised learning, their deficiencies in speed and accuracy push us to consider an alternative.
Researchers in a combined team from MIT, Microsoft, Cornell, and Google recently created a new technique called Self-supervised Transformer with Energy-based Graph Optimization (STEGO). STEGO can successfully identify and segment objects in an image down to the pixel level – all without any labeling. With its ability to “see” without labels, STEGO has tremendous potential to drive significant advances in the world of computer vision. At Betterview, we believe that property intelligence for insurers is a great use case for this technology, and we have been hard at work exploring how it could be used.
To use STEGO at Betterview, we take images, break them into sections, and make variations to each section. Imagine taking a picture of a cat, and in one case, focusing on the tail and making it black and white, and in another case, focusing on the head and leaving it in color. We know that these different image patches represent the same object, so we can put them through a neural network that will find similarities and begin to understand the object as a whole. Then, we train it to find similarities between different parts of the same image and differences with other images. After enough training, it is efficient at finding objects and similar images on its own.
We wanted to test how well STEGO distinguished roof types, so we selected a few points on a roof and asked the network to find areas that are similar. In the image below, we selected a dark roof (blue), a large, patched area (red), and a light roof type (green). Then we looked at the self-correspondence in the image to identify the roof type of every pixel. It was able to correctly determine that the other patches were of the roof type with the green cross and not the red cross.

One of our focuses at Betterview is identifying stains on roofs, and we take great care to separate them from shadows. So, we wanted to test how well STEGO could do the following:
As you can see in the image below, we marked sections of a roof that had staining (green X), shadows (blue X), and a clean roof section (red X). We found that the model was able to distinguish between these quite well and that we could use KNN (K-Nearest Neighbors, a common machine learning algorithm) correspondence to find a similar image and identify the same areas.

The use of unsupervised learning for sophisticated computer vision applications is still in its infancy, but we are encouraged by the results we have seen thus far. Soon, it may be possible to monitor, score, analyze, and manage property risk without labeling datasets. The results will help insurers streamline efficiency to better predict and prevent losses.
For two decades, technology has flooded insurers with data, the sheer volume of which has become more overwhelming than it is actionable....

A few weeks ago, I wrote a piece exploring how the P&C insurance industry might fare during a potential inflationary recession. While conceding the...

Insurers need tools to mitigate hail risk, one of the costliest and most common sources of claims. The solution is Betterview’s Hail Risk Insights,...